
Spotify 模型是团队和组织结构的一种方法,已被 Spotify 实验室推广开来。在此模型中,团队围绕功能而非技术进行组织。
Spotify 模型还普及了部落、行会以及章节的概念,这些是组织结构的其他组成部分。
参考
https://github.com/nusr/hacker-laws-zh
https://engineering.atspotify.com/2014/03/27/spotify-engineering-culture-part-1
Spotify 模型是团队和组织结构的一种方法,已被 Spotify 实验室推广开来。在此模型中,团队围绕功能而非技术进行组织。
Spotify 模型还普及了部落、行会以及章节的概念,这些是组织结构的其他组成部分。
参考
https://github.com/nusr/hacker-laws-zh
https://engineering.atspotify.com/2014/03/27/spotify-engineering-culture-part-1
KISS 原则指明了如果大多数的系统能够保持简单而非复杂化,那么他们便能够工作在最佳状态。因此,简单性应该是设计时的关键指标,同时也要避免不必要的复杂度。这个短语最初出自 1960 年的美国海军飞机工程师凯利·约翰逊 (Kelly Johnson)。
这一原则的最好例证便是约翰逊给设计工程师一些实用工具的故事。那时的他们正面临着一个挑战,即他们参与设计的喷气式飞机必须能够让普通的机械师在战场上仅仅用这些工具进行维修,因此,“直白”这个词应指的是损坏的事物本身和修复用工具的复杂度两者之间的关系,而非工程师们自身的能力水平。
KISS原则是英语 Keep It Simple, Stupid 的首字母缩略字,是一种归纳过的经验原则。KISS 原则是指在设计当中应当注重简约的原则。总结工程专业人员在设计过程中的经验,大多数系统的设计应保持简洁和单纯,而不掺入非必要的复杂性,这样的系统运作成效会取得最优;因此简单性应该是设计中的关键目标,尽量回避免不必要的复杂性。同时这原则亦有应用在商业书信、设计电脑软件、动画、工程上。
这个首字母缩略词根据报导,是由洛克希德公司的首席工程师凯利约翰逊(U-2 和 SR-71 黑鸟飞机等的设计者)所创造的。虽然长久以来,它一直是被写为“保持简洁,愚蠢”,但约翰逊将其转化成“保持简单愚蠢”(无逗号),而且这种写法仍然被许多作者使用。 词句中最后的 S并没有任何隐涵工程师是愚蠢的含义,而是恰好相反的要求设计是易使人理解的。
说明这个原则最好的实例,是约翰逊向一群设计喷射引擎飞机工程师提供了一些工具,他们所设计的机具,必须可由一名普通机械师只用这些工具修理。 因此,“愚蠢”是指被设计的物品在损坏与修复的关联之间,它们的难易程度。这个缩写词已被美国军方,以及软件开发领域的许多人所使用。
另外相类似的概念也可作 KISS原则的起源。例如“奥卡姆剃刀”,爱因斯坦的“一切尽可能简单”、达芬奇的“简单是最终的复杂性” 、安德鲁·圣艾修伯里的“完美不是当它不能再添加时,它似乎是在它不能被进一步刮除时实现的”。
“复杂”往往意味着“灾难”,“简洁”才是“效率”
参考
https://github.com/nusr/hacker-laws-zh
克努特优化原则(Knuth’s optimization principle):过早优化是万恶之源。
“过早优化是万恶之源”是软件开发届的一句名言。它来源于Donald Knuth的书《计算机编程艺术》(最早由Tony Hoare提出),以下是引用:

这句关于过早优化的原话来自于20世纪60年代出版的书。那是一个不同的时代,那时大型机和穿孔卡很常见,CPU处理周期很稀缺。所以程序优化得不好,可能会运行很长时间。
过早优化在今天该怎么理解?
今天,大多数开发团队都习惯于不断地量产代码并快速迭代,采用敏捷开发方法。如果软件中存在错误,可以很容易地将修复程序部署到Web服务器上。
现代研发过程中仍然存在过早优化的情绪。过早优化是开发人员应该一直考虑的事情,是在日常工作中应该尽量避免的事情。 防止过早优化在大型机时代适用,今天仍然适用。
一个典型的例子是一家创业公司花费大量时间试图找出如何扩展其软件以满足数百万用户。 这是一个非常值得考虑的问题,但不一定要付诸行动。 在担心处理数百万用户之前,你需要先确保100个用户喜欢并且想要使用你的产品。需要首先验证用户反馈。
因此业务模式在反复试错或高速迭代阶段,过多的优化,显得很不划算。身处业务线,经常感到被需求压得喘不过气,其实是因为产品经理会更多的关注用户需求,关注业绩提升。
随着计算机系统性能从MHz,数百MHz到GHz的增加,计算机软件的性能已经不是最重要的问题(落后于其他问题)。今天,有些软件工程师将这个格言扩展到“你永远不应该优化你的代码!”,他们发现,有时候代码怎么写似乎问题都不大。
然而,在许多现代应用程序中发现的臃肿和反应迟钝的问题,迫使软件工程师重新考虑如何将Hoare的话应用于他们的项目。
查尔斯库克(http://www.cookcomputing.com/blog/archives/000084.html)的一篇简短的文章,其中一部分我在下面转载,描述了在Hoare的陈述中的问题:
我一直认为这句话经常导致软件设计师犯严重错误,因为它已经被应用到了不同的问题领域。这句话的完整版是“We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil.”
我同意这一点。在性能瓶颈明显之前,通常不值得花费大量时间对代码进行细枝末节的优化。但是,在设计软件时,应该从一开始就考虑性能问题。一个好的软件开发人员会自动做到这一点,他们大概知道性能问题会在哪里出现。没有经验的开发人员不会关注这个点,错误地认为在后期进行一些微调可以解决任何性能问题。
Hoare和Knuth真正说的是,软件工程师在担心微观优化(比如一个特定语句消耗多少CPU周期)之前,应该先担心其他问题(比如好的架构设计和这些架构的良好实现)。即微观优化的优先级是很低的,至少低于宏观优化(架构设计)、业务需求分析等。
过早优化的原因
1、过早优化出现在一些相对容易解决的问题上。 例如,有人对应用程序有所了解,但不确定如何开发它,那么他可能花费大量时间考虑他可以处理的不重要的事情,例如徽标设计是否会使系统看起来变得高大上。我以前在国企貌似经常发生这样的事。也许这是因为没有一个能总览全局的架构设计师,导致不太懂技术的领导或者客户钻牛角尖。
2、过早优化是一种“美好的愿景”。 例如,想要开始新的爱好的人,如打羽毛球,可能会花费数小时挑选高级装备并在他们开始训练之前规划未来的行动方案,因为这样做很有趣,而且比实际开始训练更简单!在球馆时不时就能看到,除了球技其它都很专业的“爱好者”。
3、过早优化是由于未能正确对任务进行优先级排序。 例如,正在开发软件的人可能过早地优化事情,不是因为要解决(架构、性能)问题,而是因为他们根本不知道如何制定各个研发阶段的计划,识别出各个阶段应该做的工作。这也很有可能因为团队里没有一个能总览全局的架构设计师。
该怎么做?
前几天QCon的围炉夜话,听毕玄说,“09年之前,阿里的技术团队都处于陪(业务)跑状态”。公司在不同阶段,技术团队的重心会不同。初创阶段更多重视业务,业务稳定(垄断)阶段更重视技术本身。 有经验的管理者会通过职位设置,研发力量投入比例来调节业务与“优化”之间的关系。从组织的角度,是希望大多数同学做好本职工作就能很好的平衡业务与“优化”之间的关系。例如在公司发展的某个阶段,出现了架构师这个角色。
作为研发工作的具体参与者和执行者该怎么做呢?从本质上讲,在确定是否应该优化某些内容时,应该考虑以下几个因素,应该问自己的几个重要问题:
1、为什么要优化?你认为在这个阶段,这种优化是必要的,这意味着它将对你的工作产生显著的、积极的影响,还是你现在仅仅关注它,因为你试图避免处理其他事情?
2、优化的好处是什么?从优化中你能得到什么?
3、优化的成本是多少?为了进行这种优化,你需要花费什么资源?
4、优化可能带来的负面后果是什么?这种优化在将来会给你带来什么样的问题?
5、这种优化有多大可能会过时?你现在正在做的优化工作以后是否有重大意义,或者这种优化是否可能过时?请注意,仅仅因为某些东西稍后可能会过时并不意味着你现在不应该处理它,但是这种情况发生的可能性,它发生之前需要的时间以及你在此期间将获得的好处,都是你决定是否优化应考虑的因素。
6、推迟这种优化有哪些优点和缺点?推迟这个特定的优化有什么坏处吗?或许以后你会获得更多的相关信息,你会更好地处理它?
7、你还能做什么?如果你不把时间和资源花在优化上,你会把它们花在什么上?如果你有其他的事情可以做,你是否从中获益更多?
基于这些标准,可以对必须完成的不同任务进行优先级排序,并找出在哪个阶段应该处理哪些任务,以确保避免过早地进行优化。
但是,每次评估潜在任务时,不必问自己所有这些问题。小任务尤其如此,与使用所有这些标准进行评估相比,简单地完成一个2分钟的小任务可能花费更少的时间和精力。
要意识到这些考虑因素,在必要时至少在某种程度上使用它们来评估任务。任务看起来越大,需要的资源越多,或它将产生的影响越大,你应该越谨慎,应该越多地使用这些标准来评估它。
并非所有优化都为时过早
避免过早优化并不意味着你应该完全避免优化。相反,它只是意味着在决定投入资源优化某些东西之前,应该仔细考虑。
人们经常重复“过早优化是万恶之源”的观点,而没有注意到完整的引用,其中说“我们应该忘记细枝末节的优化。在97%时间,过早的优化是所有邪恶的根源。然而,我们不应该在那个关键的3%中放弃我们的机会”。
这意味着评估情况并决定优化某些东西是完全合理的,即使它处于相对较早的阶段。例如你认为小的修改可以带来显着的好处,或者优化可以解决你工作中遇到的瓶颈,或者不优化可能会导致显着的技术债务。
在关于该主题的原始引用中,说这个概念适用于大约3%的情况,但是有效优化的临界值可能高于或低于这个值。例如,一个具有共识原则是Pareto原理(二八规则),在这种情况下,表明80%的积极成果将来自你20%的工作(多做点优化工作也没问题)。
总的来说,为了避免过早优化,应该首先评估情况,并确定在那个时间点是否需要预期的优化。但是,这种方法不应成为完全避免优化的借口,而应该作为尽可能有效地确定任务优先级的方法。
总结
过早优化是试图为时尚早的阶段提高效率的行为,例如,尽管有更重要的任务需要你去处理,你却在业务的一些琐碎的方面开展工作。
过早优化是有问题的,因为它会导致你浪费资源,气馁,在你没有足够的信息时采取行动,或者陷入次优的行动过程中。
人们过早地优化事物的最常见原因是没有正确地确定任务优先级,或者过早优化对于他们来说相对容易处理,这个优化即使不必要也能接受。
为了避免过早地优化事情,在开始之前,你应该确保问问自己为什么要优化,这样做的成本和好处是什么,这种优化可能带来的负面后果是什么,等待的优点和缺点是什么,以及你还可以做些什么。
记住,这并不意味着你应该完全避免优化,而是应该仔细考虑并评估情况,然后再决定进行某种优化。
边际效应递减,应该把资源用在能使效益最大化的地方。
参考
https://cloud.tencent.com/developer/article/1525574
当时内部的过度设计有两个结果:一些设计根本不可能用上,另一些等到用上的时候,发现当初设计的时候考虑不全,还不能用,正所谓半吊子。
很赞同不要过度设计,能满足现在的需求并且做好应对未来变化的准备就够了。刚开始学习编程的时候也是力求设计完美后再开工,后来发现非常痛苦,过于复杂的设计带来了高额的成本,实际上却很难用到。最近看一本介绍Ruby语言OOP的书,提到一个概念:“不要预测未来”,深以为然。
奥卡姆剃刀原则:如无必要,切勿添加。
原文并非谈需求,就是纯粹谈程序性能优化。
Donald Knuth 1974 年在 ACM Journal 上发表的文章 “Structured Programming with go to Statements” 中写道:
We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil.
简言之,没有量化的性能测试检测到真正的性能问题之前,在代码层面各种炫技式优化,不仅可能提升不了性能,反而更会导致更多 bugs。
这条程序开发经验被奉为经典,一方面因为提出之人,另外,确实是“伟大的人生经验”。可以有多方面多层面的解读:
需求版本:先骗到合同,再扩容优化。
敏捷版本:先可用,再迭代。
雷军版本:战术上的勤奋掩盖不了战略上的懒惰。
禅师版本:空杯子里面应该先放大石头,这样能装的更多。
山寨版本:先抄袭,后修改。
创业版本:先上线,后优化。
婚姻版本:先结婚,后恋爱。
总之,他们强调先可用、可行、可赚,然后在了解到真正的问题之后,再做调整和优化。
总之,这是典型的贪心算法,尽管并不一定保证最终最优,但能让你浪费最少。
We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil.
字面意思是97%优化是不值得也不应该做的,“过早”的那类优化是指这97%,关键点的优化,也就是剩下的3%仍是绝对必要的,虽然作者并没有直接说“这3%应该尽早做”,但某种程度上“we should not pass up our oppurtunities”大概已经包含了这层意思。作者并不反对优化,而且强调作关键优化的必要性。直白地说,他的意思是:不要浪费时间做那些根本不重要的优化。
很多时候,代码架构的很大部分就是关于如何优化,但把这个部分做对是很有必要的,这是那3%里的情况,并不“过早”,因为系统性能和伸缩性其实主要靠好的架构设计,而不是局部优化。
因为需求会变。
很多时候可能你都不知道需求是什么,原型已经开始架构了。
用户可能也不知道他们的真实需求,很多时候当他们看到原型时,才逐步明确需求。常规领域中,90%以上的优化都产生不了用户可感知的价值,所以不要在早期浪费时间,事后进行剖析和优化就是了。
Make it Work.
Make it Right.
Make it Fast.
不要跳过前面两个直奔第三个!
先第一个版本尽快上线抢占市场再说,大多数没赚到钱的项目都活不过几个月,赚到钱了才有闲情在第2、第3个版本慢慢优化,有钱了还可以请技术大牛来优化。
英文”premature optimization”,我觉得“过早”翻译得不确切,premature实际上不是指一个时间概念,而是指没有充分证据的、未经论证的、盲目的优化。应该叫“盲目优化是万恶之源”。用中国老话就是要“不见兔子不撒鹰”。
什么叫“过早”?这个没说清楚。
我看不同的人有不同定义,这里我说两个最重要的:
1. 优化,一定要有证据,这是最重要的。最明显的证据就是跑分,要想跑分就得先通过测试,否则错误的程序谈跑分没有任何意义。要想通过测试,程序就必须能够正确运行,要想正确运行,程序就必须起码写完能运行。换句话说,“没有足够证据支撑的优化是万恶之源”。 2. 第二个,任何性能上的优化都会损失可读性和可维护性,这是必然的。过早优化就可能需求还没稳定。如果需求大改的话,优化也就废了。如果需求小改,那么优化前的代码肯定比优化后的代码容易改。这应该也是一个因素。
总之应该就是想迭代思维那样,“允许不足,增量弥补”,而不是一锤子买卖,那项目的抗风险能力就很低了。
像生命一样会进化的系统才是最适应环境的系统!不会随着环境的变化而进化的物种都被淘汰了。
1个程序跑1分钟,要不要优化?刚毕业的学生会说:太慢了,要优化。
但如果加上一个条件,这个程序只占据整个流程的1%,其余流程要跑3天,你还会不会优化它?
不同场景,不同需求,不同系统,要具体分析,抓大放小。
就像我小时候穿的衣服,我妈总给我买大一号的,可我的生长速度没那么快,每次都是穿烂了都还大。现在轮到我女儿了,姥姥奶奶再给买衣服,我都是让她们直接买正好的就行。
「过早的优化是万恶之源」这句话是我非常喜欢的一句话。虽然是起源于软件开发领域的一句话,但我发现在工作和生活中,在时间管理中,在恋爱中,都有过早优化的问题,牢记这句话可以解决很多问题,甚至是根本性的问题。简单地说,就是计划赶不上变化。
参考
https://www.zhihu.com/question/24282796
怎么理解“premature optimization is the root of all evil”?
个人经验是在web开发中,如果早期不考虑数据库结构,各种数据接口的话,后期的扩展和优化会很难做,这句话是不是放之四海而皆准呢?如果不是这段Donald Knuth的名言该如何理解?
你的经验没错。如果一开始把系统的每个部分都只做到20%的水准,那么后期你会发现80-20规则不成立,根本没有什么瓶颈可以”优化”,你得把每个部分都提升到50%水准再说别的。 问题是Don Knuth不是普通程序员,他的基线可能是80%,而他的优化是从80%提升到95%。而很多人把他的话拿来支持自己只做到20%。

我想,Donald Knuth这里说的是为时过早的优化,而不是指早期的设计,你说的数据库结构,各种接口等等,应该是设计范畴的,Design,而不应该是优化,Optimiziation。
再说这一句话,优化往往是针对某一个点,某一个性能瓶颈而进行的,而在早期,这个点根本不存在,或者在后期可能都会发生改变,之前的优化功夫都白费了。
他这里说的是优化,不是你理解的设计。设计当然应该先做,而优化则是后期的工作。
参考
https://www.zhihu.com/question/20136075
优化的第一个原则是:不要去动它。优化的第二个原则(只对专家来说)是:还是不要去动它。衡量两次,优化一次。
我们把过早优化定义为以性能的名义使设计和代码更加复杂,更不可读,而我们的这些努力并没有被需要的性能检验证明是恰当的(如实际的测量结果和与性能目标对照),并且因此,按定义,将未经证实的价值加到程序中。时常,不必须的和未经测试的努力优化根本不能使程序更快。
总是记住:让正确的程序更快,比让快速的程序正确要容易太多。
所以,缺省情况下,不要集中在让代码更快上,首先把注意力放在使代码尽可能性的清楚和可读上。清楚的代码易于书写正确,易于理解,易于重构—并且易于优化。复杂化,包括优化,总是在稍后引入—并且只在必要的时候。
这儿有两个原因为什么频繁的过早优化一点也不能使程序更快:
首先,我们的程序员在估计什么样的代码会快些或慢些,代码中什么地方是瓶颈方面是声名狼籍的差。这些程序员包括我们(这本书的作者),也包括你。考虑:现代的计算机有极其复杂的计算模型,通常包括:管道处理单元在并行的工作,很深的缓存层次,预测执行。指令预测…这些仅仅在CPU芯片的层次。在硬件的基础上,编译器在将代码翻译成机器码时,将会用最好的猜测来利用硬件。唔,在所有的复杂性上,仅仅是你的猜测。所以,你如果仅仅是猜测,只有很小的机会才能使你在病态的目标上的微调有显著的提高。所以,测量在优化之前,优化的目标在测量之前。你的注意力应该在优先级为#1的条目 — 为人写代码,直到证明必须优化。(当有人请你优化的时候,请他出示证据)。
第二,在现代的程序中,许多日益增加的操作并不在CPU的范畴内。它们也许属于内存的范畴,网络的范畴,硬盘的范畴,正在等待WEB服务,或者正在等待数据库。在这样的操作中调整应用程序的代码最多只是等得更快。这也意味着程序员总是浪费宝贵的时间在改进那些不需要改进的代码,而没有通过所做的改进增加价值。
当然,确实需要优化某些代码的那天终会到来。当你这样做的时候,请首先看能不能做算法优化(条款7),并试着封装和模块化优化(举例来说,将优化包装在函数或者类中,条款5和条款11),同时在注释中清楚地说明优化的原因和所参考的算法。
一个初学者通常的错误是自负的写新代码,以牺牲代码的可理解性为代价换来执行速度的优化。通常,这产生出一大堆糟糕的代码,即使一开始是正确的,也是难于阅读和更改的。
KISS(Keep It Simple Software保持简单的软件)原则:正确优于快速,简单优于复杂,清楚优于机灵,安全优于危险。
即,计算机软硬件系统是一个复杂系统,不是说你想当然地、拍脑门地优化了某段代码后,整个系统的性能就突然提高了,应该在性能测试之后,再针对热点进行优化。
参考
http://coder.zoomquiet.top/data/20120222104457/index.html
过早优化对大的问题在于:
活在当下,实实在在做好手头的事,是避免“过早优化”最好的方法之一。
参考
Telnet is commonly used to check if a TCP connection to a specific port succeeds — essentially testing whether the port is open and reachable. Note that telnet itself is TCP-based, so it cannot test UDP sockets.
Syntax Basic:
telnet [options] host [port]More complete:
telnet [-8acdEfFKLrx] [-b<host_alias>] [-e<escape_char>] [-k<realm>] [-l<user>] [-n<tracefile>] [-S<tos>] [-X<authtype>] [host [port]]Quick background Telnet is the classic remote login client based on the TELNET protocol. It lets you run commands on a remote server as if you were sitting in front of it. You log in with username/password, but everything (including credentials) is sent in clear text — very insecure. Most modern Linux servers disable telnet and use SSH instead.
That said, curl can test HTTP services, and telnet can too (more on that below).
For UDP testing, use:
Common options
telnet -e ^X host port telnet -l root 192.168.1.10In interactive mode After connecting, press Ctrl+] to enter telnet command mode. Useful commands:
Examples
telnet 192.168.120.206(or by domain: telnet www.baidu.com)
If it fails:
telnet 127.0.0.1 6379Outcomes:
HTTP example:
telnet example.com 80
GET / HTTP/1.1
Host: example.com
(then hit Enter twice)Redis example:
telnet 127.0.0.1 6379
PING→ +PONG
Typical telnet service config (/etc/xinetd.d/telnet)
service telnet
{
disable = no
flags = REUSE
socket_type = stream
wait = no
user = root
server = /usr/sbin/in.telnetd
log_on_failure += USERID
}Restrict access:
only_from = 10.0.0.2
no_access = 10.0.0.{2,3,4}
access_times = 9:00-12:00 13:00-17:00
bind = 10.0.0.2Limitations
Modern role: Telnet is best positioned as a quick TCP port/text-protocol debugging tool, not a login method.
Related tools
功能说明:telnet可以用于测试TCP socket链接是否连通(某个TCP端口是否开放)。但telnet不能测试 UDP socket链接,因为telnet基于TCP 协议,不支持 UDP。
语 法:
1 基本命令格式
telnet [选项] 主机 [端口]
2 复杂命令格式
telnet [-8acdEfFKLrx][-b<主机别名>][-e<脱离字符>][-k<域名>][-l<用户名称>][-n<记录文件>][-S<服务类型>][-X<认证形态>][主机名称或IP地址<通信端口>]
补充说明:
1telnet一般用于登入远程主机,与之类似的工具是ssh。telnet程序是基于TELNET协议的远程登录客户端程序。Telnet协议是TCP/IP协议族中的一员,是Internet远程登陆服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的 能力。在终端使用者的电脑上使用telnet程序,用它连接到服务器。终端使用者可以在telnet程序中输入命令,这些命令会在服务器上运行,就像直接在服务器的控制台上输入一样。可以在本地就能控制服务器。要开始一个 telnet会话,必须输入用户名和密码来登录服务器。但是telnet因为采用明文传送报文,安全性不好,很多Linux服务器都不开放telnet服务,而改用更安全的ssh了。
2 curl可以测试HTTP服务,telnet也可以测试HTTP服务。
3 那怎么测UDP?可以使用以下工具:
选 项:
-4 强制IPv4地址解析
-6 强制进行IPv6地址解析
-8 允许使用8位字符资料,包括输入与输出。
-a 尝试自动登入远端系统(已很少使用)。
-b<主机别名> 使用别名指定远端主机名称。
-c 不读取用户专属目录里的.telnetrc文件。
-d 启动排错模式。
-e<脱离字符> 设置escape字符(默认是 Ctrl + ]),用于优雅退出telnet。例如:telnet -e ^X host port
-E 滤除脱离字符。
-f 此参数的效果和指定”-F”参数相同。
-F 使用Kerberos V5认证时,加上此参数可把本地主机的认证数据上传到远端主机。
-k<域名> 使用Kerberos认证时,加上此参数让远端主机采用指定的领域名,而非该主机的域名。
-K 不自动登入远端主机。
-l<用户名称> 指定要登入远端主机的用户名称(主要用于传统 telnet server)。例如:telnet -l root 192.168.1.10
-L 允许输出8位字符资料。
-n<记录文件> 指定文件记录通信数据(调试用)。用法:telnet -n telnet.log host port
-r 使用类似rlogin指令的用户界面。
-S<服务类型> 设置telnet连线所需的IP TOS信息。
-x 假设主机有支持数据加密的功能,就使用它。
-X<认证形态> 关闭指定的认证形态。
telnet交互模式下的常用命令:
连接到远程服务后,按:
Ctrl + ]
进入 telnet 命令模式。常用命令有:
quit 退出 telnet
close 关闭当前连接
status 查看连接状态
open host port 打开新连接
set localecho 本地回显
toggle crlf 切换 CRLF
实 例:
1 连接到远程主机的telnet服务
telnet 192.168.120.206如果连接失败,排查步骤如下:
如果主机已经启动,确认主机上是否开启了telnet服务?(使用netstat命令查看,TCP的23端口是否有LISTEN状态的行),可以使用以下命令启动telnet服务:service xinetd restart
主机名可以换成域名,例如:
telnet www.baidu.com2 测试 TCP 连接是否可达
telnet 127.0.0.1 6379可能出现以下结果:
Connection refused,意味着端口未监听Connection timed out,意味着网络 / 防火墙问题这是 telnet 最常见用途(80% 场景)。
3 作为“通用 TCP 客户端”
telnet 不关心上层协议,只管:把你输入的字符,通过 TCP 发给对方。所以你可以用它来测试:HTTP、SMTP、Redis(文本命令)或自定义 TCP 文本协议。
示例:测试 HTTP
telnet example.com 80然后输入:
GET / HTTP/1.1
Host: example.com示例:测试 Redis
telnet 127.0.0.1 6379输入:
PING
返回:
+PONG
telnet服务常用配置:
service telnet
{
disable = no #启用
flags = REUSE #socket可重用
socket_type = stream #连接方式为TCP
wait = no #为每个请求启动一个进程
user = root #启动服务的用户为root
server = /usr/sbin/in.telnetd #要激活的进程
log_on_failure += USERID #登录失败时记录登录用户名
}
#配置允许登录的客户端列表
only_from = 10.0.0.2 #只允许10.0.0.2登录
#配置禁止登录的客户端列表
no_access = 10.0.0.{2,3,4} #禁止10.08.0.2、10.0.0.3、10.0.0.4登录
#设置开放时段
access_times = 9:00-12:00 13:00-17:00 # 每天只有这两个时段开放服务
#配置用户只从某个地址登录telnet服务
bind = 10.0.0.2telnet的局限性:
现代环境中 telnet 的“正确定位”是TCP 端口 / 文本协议的调试工具,而不是登录工具。
其他相关的网络工具:
Here’s the man page for the telnet command in an old Ubuntu release:
http://manpages.ubuntu.com/manpages/karmic/man1/telnet-ssl.1.html
Scroll all the way to the bottom and you’ll find this under BUGS:
The source code is not comprehensible.
The source package is here: http://packages.ubuntu.com/source/dapper/netkit-telnet
Download it and take a look — it’s genuinely hard to read. A quick scan reveals at least these issues:
#ifndef B19200
#define B19200 B9600
#endif
#ifndef B38400
#define B38400 B19200
#endifIt’s legitimately tough to follow.
Still, huge respect to whoever decided to call out the source code’s readability as an official BUG in the man page.
(via coolshell.cn)
You can use Tinker to verify if your database connection is working:
php artisan tinkerThen inside Tinker, run:
DB::connection()->getPdo();If the connection succeeds, you’ll get back PDO instance details. If it fails, you’ll see the actual error message (usually something helpful like credentials issues or host unreachable).
你可以使用 Tinker来测试数据库连接:
php artisan tinker然后在Tinker中运行:
DB::connection()->getPdo();如果连接成功,你应该会看到与PDO相关的信息。如果连接失败,会显示相应的错误信息。
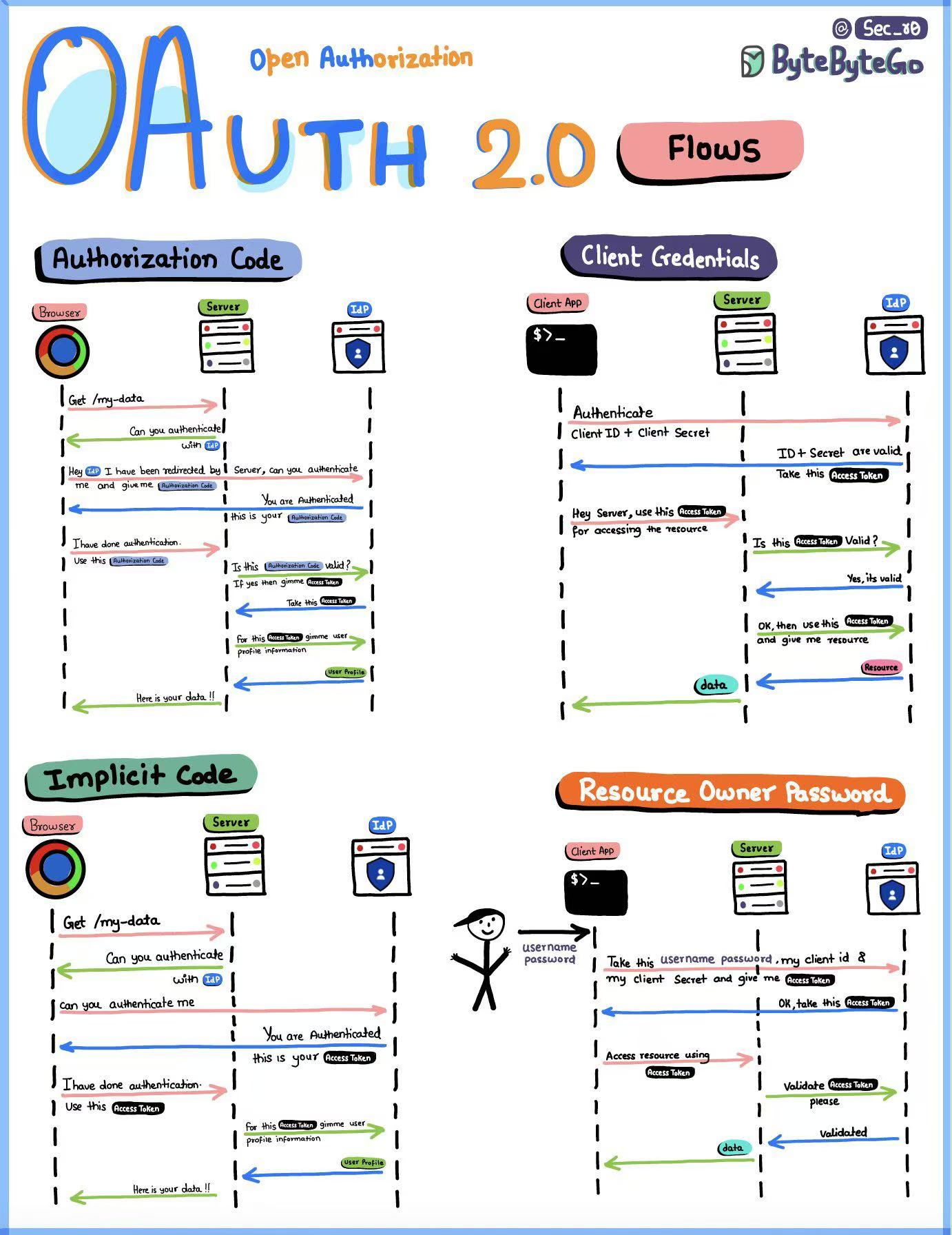
授权码授权模式和隐式授权模式的区别:
相信你的系统中也一定会有手机注册以及发送短信验证码的功能。那么验证用户填写的手机号是否规范合法就是我们完成后续功能的第一步。propaganistas/laravel-phone包为我们提供了非常强大且可靠的电话验证功能,并且适用于全球所有国家的号码验证。
安装
composer require propaganistas/laravel-phone
配置
服务提供者会被 Laravel 自动发现。在语言目录lang中,为每个 validation.php 语言文件添加一条额外的翻译:
'phone' => 'The :attribute field must be a valid number.',
在线工具网站
https://laravel-phone.herokuapp.com用于测试Laravel-Phone包中的电话号码验证组件。
你可以在验证规则数组中使用phone关键字,或者使用 Propaganistas\LaravelPhone\Rules\Phone规则类来以更具表现力的方式定义规则。 要限制国家/地区,你可以明确指定允许的国家/地区的代码:
'my_input' => 'phone:US,BE',
// 'my_input' => (new Phone)->country(['US', 'BE'])或者为了使功能更加灵活,还可以与另一个包含国家/地区代码的数据字段进行匹配。例如,要求用户的电话号码与用户提供的居住国家/地区匹配。请确保国家/地区字段的名称与电话号码字段的名称相同,但附加”_country”后缀以便laravel-phone包自动识别:
'my_input' => 'phone',
// 'my_input' => (new Phone)
'my_input_country' => 'required_with:my_input',或者将自定义的国家/地区字段名称作为参数传递给验证器:
'my_input' => 'phone:custom_country_field',
// 'my_input' => (new Phone)->countryField('custom_country_field')
'custom_country_field' => 'required_with:my_input',注意:国家代码应符合ISO 3166-1 alpha-2标准。
为了支持除白名单国家/地区之外的任何有效国际格式的电话号码,请使用INTERNATIONAL参数。当你预期接收来自特定国家/地区的本地格式号码,但同时也希望接受任何其他正确输入的国外号码时,此功能会非常有用:
'my_input' => 'phone:INTERNATIONAL,BE',
// 'my_input' => (new Phone)->international()->country('BE')要指定电话号码类型的约束,请将允许的类型附加到参数后面,例如:
'my_input' => 'phone:mobile',
// 'my_input' => (new Phone)->type('mobile')
// 'my_input' => (new Phone)->type(libphonenumber\PhoneNumberType::MOBILE)最常见的类型是移动电话mobile和固定电话fixed_line,但你可以随意使用此处定义的任何电话号码类型。
在电话号码类型名称前加上感叹号即可将其列入黑名单。请注意,你不能同时使用白名单和黑名单:
'my_input' => 'phone:!mobile',
// 'my_input' => (new Phone)->notType('mobile')
// 'my_input' => (new Phone)->notType(libphonenumber\PhoneNumberType::MOBILE)你还可以使用LENIENT参数启用宽松验证。启用宽松验证后,系统只会检查数字的长度,而不会检查实际的运营商模式:
'my_input' => 'phone:LENIENT',
// 'my_input' => (new Phone)->lenient()为了方便对Eloquent模型属性进行自动类型转换,我们提供了两个转换类:
use Illuminate\Database\Eloquent\Model;
use Propaganistas\LaravelPhone\Casts\RawPhoneNumberCast;
use Propaganistas\LaravelPhone\Casts\E164PhoneNumberCast;
class User extends Model
{
public $casts = [
'phone_1' => RawPhoneNumberCast::class.':BE',
'phone_2' => E164PhoneNumberCast::class.':BE',
];
}这两个类都会自动将数据库中的值转换为PhoneNumber对象,以便在你的应用程序中进一步使用:
$user->phone // PhoneNumber object or null
在设置值时,它们都接受字符串值或PhoneNumber对象。RawPhoneNumberCast会将数据库值更改为原始输入号码,而E164PhoneNumberCast会将格式化的E.164电话号码写入数据库。
对于RawPhoneNumberCast类,需要指定电话号码所属国家/地区,才能正确地将原始号码解析为PhoneNumber对象。对于E164PhoneNumberCast类,如果待设置的值并非已采用某种国际格式,则也需要指定电话号码所属国家/地区,才能正确地转换该值。
这两个类以相同方式接受类型转换参数:
public $casts = [
'phone_1' => RawPhoneNumberCast::class.':country_field',
'phone_2' => E164PhoneNumberCast::class.':BE',
];重要提示:这两种类型转换都需要有效的电话号码才能顺利地进行PhoneNumber对象的转换。请在将电话号码设置到模型之前进行验证。有关如何验证电话号码,请参阅上节“验证请求字段”。
⚠️ 属性赋值和E164PhoneNumberCast类
由于E164PhoneNumberCast的特性,如果电话号码不是国际格式,则需要提供有效的国家/地区代码。由于Laravel在设置属性时会立即执行类型转换,因此请务必在设置电话号码属性之前设置国家/地区代码属性。否则,E164PhoneNumberCast将遇到空的国家/地区代码值并抛出意外异常。
// 错误
$model->fill([
'phone' => '012 34 56 78',
'phone_country' => 'BE',
]);
// 正确
$model->fill([
'phone_country' => 'BE',
'phone' => '012 34 56 78',
]);
// 错误
$model->phone = '012 34 56 78';
$model->phone_country = 'BE';
// 正确
$model->phone_country = 'BE';
$model->phone = '012 34 56 78';PhoneNumber电话号码可以封装在Propaganistas\LaravelPhone\PhoneNumber类中,从而为其添加实用的方法。在视图中或保存到数据库时,可以直接引用这些对象,它们会优雅地降级为E.164格式。
use Propaganistas\LaravelPhone\PhoneNumber;
(string) new PhoneNumber('+3212/34.56.78'); // +3212345678
(string) new PhoneNumber('012 34 56 78', 'BE'); // +3212345678或者,你可以使用phone()辅助函数。它会返回一个Propaganistas\LaravelPhone\PhoneNumber实例,如果提供了$format参数,则返回格式化后的字符串:
phone('+3212/34.56.78'); // PhoneNumber instance
phone('012 34 56 78', 'BE'); // PhoneNumber instance
phone('012 34 56 78', 'BE', $format); // string格式化号码
可以多种方式格式化PhoneNumber实例:
$phone = new PhoneNumber('012/34.56.78', 'BE');
$phone->format($format); // 见libphonenumber\PhoneNumberFormat
$phone->formatE164(); // +3212345678
$phone->formatInternational(); // +32 12 34 56 78
$phone->formatRFC3966(); // tel:+32-12-34-56-78
$phone->formatNational(); // 012 34 56 78
// 格式化后,即可直接从提供的国家/地区拨打该号码
$phone->formatForCountry('BE'); // 012 34 56 78
$phone->formatForCountry('NL'); // 00 32 12 34 56 78
$phone->formatForCountry('US'); // 011 32 12 34 56 78
// 格式化后的号码在手机上可以直接点击,然后可以用手机直接从指定的国家/地区拨打该号码
$phone->formatForMobileDialingInCountry('BE'); // 012345678
$phone->formatForMobileDialingInCountry('NL'); // +3212345678
$phone->formatForMobileDialingInCountry('US'); // +3212345678号码信息
获取一些关于该号码的信息:
$phone = new PhoneNumber('012 34 56 78', 'BE');
$phone->getType(); // libphonenumber\PhoneNumberType::FIXED_LINE
$phone->isOfType('fixed_line'); // true (or use $phone->isOfType(libphonenumber\PhoneNumberType::FIXED_LINE) )
$phone->getCountry(); // 'BE'
$phone->isOfCountry('BE'); // true等值比较
比较两个号码相同还是不同:
$phone = new PhoneNumber('012 34 56 78', 'BE');
$phone->equals('012/34.56.76', 'BE') // true
$phone->equals('+32 12 34 56 78') // true
$phone->equals( $anotherPhoneObject ) // true/false
$phone->notEquals('045 67 89 10', 'BE') // true
$phone->notEquals('+32 45 67 89 10') // true
$phone->notEquals( $anotherPhoneObject ) // true/false免责声明:不同应用程序处理电话号码的方式各不相同。因此,以下内容仅供参考,旨在启发思考;我们不提供相关技术支持。
将电话号码存储在数据库中一直是一个值得探讨的问题,而且并没有一劳永逸的解决方案(没有银弹)。一切都取决于你的应用程序需求。以下是一些需要考虑的因素,以及一个实现建议。你理想的数据库设置可能需要结合以下列出的一些要点。